[This article is a very easy and simple introduction to the concepts of lighting in games, it´s history and the tendency this field is following]
It is certainly impossible to talk about lighting models in realtime 3D graphics without a mention to
John Carmack, co-founder of
Id Software, and one of the pioneers of the modern gaming industry.
In 1994, Id Software released one of their biggest hits:
Doom, using an advanced version of the
Wolfenstein-3D engine. One of it´s biggest technical advantages were the more immersive pseudo-3D environment, better graphics and more freedom of movement.
The game was absolutely great, but the 3D environment was, in fact, a 2D space drawn as 3D, and it lacked a real lighting system, as you can see in the following screenshot:

This two issues were solved in a later Id Software´s release:
Quake, considered to be one of the first
real 3D videogames, and also one of the first games to use a pre-computed lighting model
Let there be light
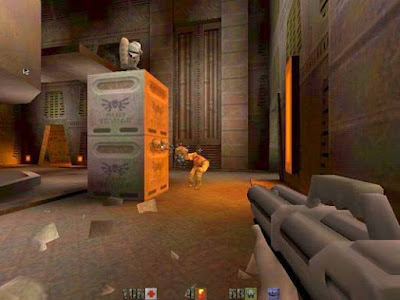
First, a quick look at a Quake screenshot:
 [A note for principiants:]
Comparing it with the Doom picture, the first change is that here, everything is 3D. No sprites at all, but polygons, points and textures. And this is crucial, as it makes possible the second change, which is obviously the lighting system. Remember that sprites are just pictures that are copied to the screen when needed, already including their illumination. That´s why they doesn´t work well with other environment lights. Polygons and vertices, unlike them, can hold properties to feed a lighting engine, as position, orientation, etc.
[A note for principiants:]
Comparing it with the Doom picture, the first change is that here, everything is 3D. No sprites at all, but polygons, points and textures. And this is crucial, as it makes possible the second change, which is obviously the lighting system. Remember that sprites are just pictures that are copied to the screen when needed, already including their illumination. That´s why they doesn´t work well with other environment lights. Polygons and vertices, unlike them, can hold properties to feed a lighting engine, as position, orientation, etc.
In the screenshot you can see an orange light source coming through the door on the right, lighting the box in the center and the character in the middle. The box also projects a shadow to the floor and there are additional shadows in the walls too. In short, Quake had a very decent lighting model, providing the game with a much more real lighting, and therefore, a better immersion. Let´s see how all this stuff is done...
Vertex lighting. Enough even for quake?
One of the first approaches to 3D lighting models is the so-called
Vertex Lighting, which is well covered in
this nVidia article. Basically, it computes the amount of light received by every vertex of every polygon that composes a 3D model, and uses that amount of light to modulate the color of the vertex and therefore the interpolated color through the polygon.
It works well for very high detail 3D models, where the distance between vertices is small, and therefore the sampling frequency is high. BUT, for performance reasons, 3D games cannot have an unlimited level of geometry detail. Even more in 1996. The following picture shows an approximation to the level of geometry used in Quake:

As you can see, it has a VERY LOW level of detail. Take a look at the shadow the box projects to the floor. It is a gradient through the geometry, where no vertex appears, so that gradient cannot be hold by Vertex Lighting.
Even now it´s impossible to use enough detail in geometry to make Vertex Lighting usable as the only lighting model.
So, now what?
The answer is to use some kind of system that allows us to store lighting information in the inner points of a polygon (not only at the vertices), without increasing the real detail of geometry. Think about it as a two dimensional table with numeric values storing the amount of light received by every inner point of the polygon.
Some questions come out quickly now:
1.- How big that table should be?
Of course this comes to a sampling frequency problem: the more samples we take (points per inch, or whatever), the more detail in the lighting.
2.- How do we relate the inner points of the polygon with the entries on the table?
Will see this later.
3.- Will the PC have room for so much information?
Let´s make a quick calculation for Quake: maybe 1000 polygons per scene, with a lighting table of 32x32 samples, makes a total amount of 1.024.000 floats. What is more or less 4 Mb of memory.
Nowadays, it doesn´t look so much, but remember that Quake was released in 1996, when the typical PCs where intel 486 or Pentium in best cases, with a clock frequency between 66 and 133Mhz, and with a system memory of maybe 8Mb or 16Mb. So, wasting one half or a quarter of the total available memory in lighting is definitely not feasible.
4.- Will the PC have enough computing power for that lighting system?
Definitely not. Calculating the lighting for a single point can take a lot of operations, and it would have to be done 1.024.000 times per frame.
Then, how this damn Quake works?
That´s the question. How does a PC like a Pentium 66Mhz handle all this lighting and graphics in realtime?
Easy,
it doesn´t.
If you think a little bit, you will realize that though you can move freely through your room, lights normally don´t move, and in most cases, objects neither. So, why not to
pre-compute the lighting of static objects just once, storing the results somewhere? That´s what Quake does.
It has a level editor which allows you to place lights through the scene, and calculates the static lighing of the environment offline, storing the results for a later realtime usage.
That saves all the realtime calculations, solving the problem of question #4, but it doesn´t solve the memory problem of question #3, and again it doesn´t explain question #2.
Questions #2 and #3. Lightmaps on the stage
Take a look at the lighting tables which store the results of the offline lighting calculations done by the level editor. Wait a moment... a 2D table storing numeric values... mmmmhhhh... I have seen this before... Digital pictures or Textures are very similar to this stuff: 2D tables of data... And... wait a moment! If I store those results in Textures or digital pictures, instead of simple 2D tables....
Yes, that´s the point. If you store that information in textures, you can:
1.- Use compression algorithms to reduce the amount of memory needed. Lighting will be very similar in many places so block packaging and compression will save A LOT of memory. This helps with the question #3.
2.- You already have a system to relate the inner points of a polygon with the contents of a texture: TEXTURE COORDINATES. This solves question #2.
That´s right.
Lightmaps are special textures which store lighting information, instead of the appearance of a base material. Just like this one:

They were widely used in Quake to store lighting and are a great way to add realism to your 3D engine. Since then, Lightmaps are a must in any modern 3D application.
Although there have been some approaches to Dynamic Lightmapping, lightmaps are normally used to store
static lighting information only, combined later other kind of lighting that cannot be static, for moving lights or objects: vertex lighting, shadow mapping, shadow volumes, vertex and pixel shaders, etc...
Textures Rock!
Once we have a way to relate points on the surfaces of 3D objects with texels on a texture, we can store any kind of information on them: bumpiness, shininess, shadows, specular components, etc.
Take a look at the following example taken from
here (a very good article on shading). This image belongs to the
Valve Engine used in games like Half-Life.
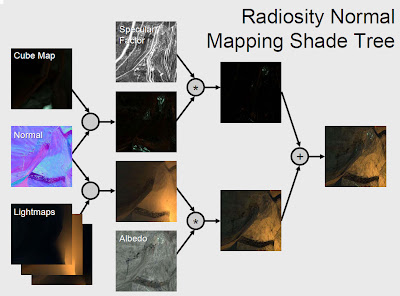
You can see that they use a whole bunch of different textures to store different kind of information about surfaces, getting very good results, as seen in Half-Life 2.
Don´t break the magic
The fight 3D programmers are involved in, since the years of Doom, is nothing more than
realism. In other words, don´t break the magic with strange or unaccurate lighting. Try to be accurate and look into the details that make a picture look real. For instance, take a look at this pic:

Another example:

Those pictures use a very simple geometry, and almost no textures... So, what makes them so damn real?
Easy...
PHYSICALLY CORRECT LIGHTING
Lighting is everything. It determines the way objects look more than anything else we can use in computer graphics. That images look real because they use a lighting engine with concepts like radiosity or global illumination.
Lighting is not just about finding the amount of light between 0 and 1. A real lighting engine uses photometric lights, with real physical properties, and propagates light correctly through the scene, reflecting and refracting each ray of light. A real amount of light is between -infinity and + infinity, and a real High Dynamic Range display system maps those values to the screen.
The need for a pre-computed illumination model
It´s clear that the next challenge in computer graphics is not realism, but to be able to make all this calculations in realtime. To allow illumination to be really dynamic. With no tricks at all... just real dynamic lighting.
Of course, the amount of calculations to make is huge. So the question is:
will we make it in the next few years or will we still need a pre-computed (static) illumination system?
Let´s make a quick assumption. Nowadays, a very good lighting engine like
V-Ray can take hours to calculate the illumination of a scene. Let´s say, 10 hours (what is not exagerated at all). We are able to generate a new image every 36.000 seconds.
So, if we want to make those calculations at, maybe, 60 fps (one image every 0.016 secs), we would need a computing power more than 2 million times bigger than the power we have right now, what seems to be a little bit too much. Of course we cannot think the evolution of computing power will be linear, as newer techniques will for sure be discovered, speeding thiings up, but anyway the leap forward is huge and such a thing doesn´t seem to be feasible soon.
So, we will still need pre-computed systems for quite a little bit yet.
Anyway, who knows!

















